简介
- Hamming Embedding是在论文:Hamming embedding and weak geometric consistency for large scale image search中提出,该论文主要是提出了
Hamming embedding,用于解决codebook size大小都会导致检索质量较差的问题;提出了weak geometric consistency(WGC),使得检索对特征的缩放和旋转更加鲁棒。 - 在这篇博客中,主要介绍
hamming Embedding,不对WGC进行介绍。同时也会介绍图像检索中一些常用的知识点,如tf-idf,BoF model等。
补充知识
TF-IDF(term frequency–inverse document frequency)
- tf-idf是一种用于信息检索与数据挖掘的常用加权技术,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
- 一般来说,一个词在一个文档中出现的频率越高(在该文档中所有词中所占比例),或者这个词在特定场景(文档)下出现的频率越高,则说明这个词对是越关键的。
- tf-idf的计算主要有2个步骤
计算词频(tf)
- 词频为在词在该文档中出现的总次数,为了防止文档词数对词频造成影响,一般会除以该文档的总词数。
计算逆文档频率(idf)
- 因为有的很常用的词汇在每个文档中都会出现,因此不能将其作为关键词,idf计算为
$$idf = log \frac {N} {N_c + 1}$$
其中$N$为语料库中所有文档的数量,$N_c$为包含该词的文档的数量,1是为了防止0除现象。按照之前的理解,如果该词只在特定文档中出现,则说明它可以被视为关键词。
计算tf-idf
- 将tf与idf相乘即可得到
tf-idf。 - 计算tf-idf之后,可以进行排序,找到对应的关键字,这也是其应用之一。
Bag-of-feature model
- 在文本分析中,有
bag-of-word model,即首先构建一个基于单词的bag,之后每句话都可以用基于该bag中的word的频度进行表征,举例如下:
假设一个dictionary为D:{1:”well”, 2:”accurate”, 3:”fast”, 4:”as”, 5:”and”, 6:”model”, 7:”is”, 8:”The”, 9:”a”}
对于一句话S:”The model is fast as well as accurate.”
S用D可以表示为[1,1,1,2,0,1,1,1,0]。
- 每个数值都表示D中对应位置word在S中出现的次数,从而可以将文本用向量进行表示,便于计算机处理,如果两个句子对应的向量表示的距离很小,则可以认为它们的相似度很高。
- 如果要扩展到图像任务中,则可以引入
bag-of-feature model,与之前的区别只是将word换成了feature。 - 基于BOF的
image representation主要有以下两个步骤。
feature representation
- 给定一个图像,对于每个图像,我们都可以提取大量特征点,同时由特征点得到大量特征向量,可以使用sift、surf、orb等方法(其中sift最常用)。从而构建了一个feature bag。
codebook generation
- 在生成大量feature之后,就需要根据这些feature生成大量codewords,从而构建整个codebook。一个codeword可以作为若干个相似的
feature vector的表征。 - 可以使用简单的
kmeans clustering对所有的feature进行处理,假设聚类簇数为$K$,则codebook size就是$K$,聚类完成之后,所有聚类中心就是所有的codewords。
quantize features
- 对于一幅新的图像,首先提取特征,假设个数为$N$,对于每一个特征,找到它在codebook中的
k近邻,说明图像中可以用该codeword进行表示,对所有特征进行这样的操作后,类似于文本中,可以得到一个$1 \times K$的向量,记为$V$,表示该图像包含特定的codeword的数量,同时有$sum(V)=k \cdot N$。如果两个图像的image representation距离很小,则可以认为它们是相似的。 - 上述表示中,有时候找到最近邻后,发现最近邻codeword与feature的距离仍然很大,即没有codeword与该feature对应,此时更适合的做法是使得该feature不对最后的
表征向量做贡献,即$f(x,y)=0$。两种匹配函数分别表示如下。
$$f_{kNN}(x,y) = \begin{cases}
1,\;if\;x\;is\;a\;kNN\;of\;y \\
0,\;otherwise
\end{cases} $$
$$f_ \varepsilon (x,y) = \begin{cases}
1,\;if\;d(x,y) < \varepsilon \\
0,\;otherwise
\end{cases} $$
- 如果考虑到
tf-idf,即越稀缺的word的比重应该越大,可以每个特征对结果的贡献由示性函数修改为下面的公式
$$f_{tf - idf}(x,y) = (tf - idf(q(y)))^2 \delta _{q(x),q(y)}$$
在得到图像的representation(score)之后,一般都会使用L1 norm或者L2 norm对待检索图像的score(那个$1 \times K$的图像)进行normalization。
相对于直接使用ANN进行匹配,BoF model最大的优势就是大大减少了计算内存要求。
reference
- https://en.wikipedia.org/wiki/Bag-of-words_model_in_computer_vision
- http://www.cs.unc.edu/~lazebnik/spring09/lec18_bag_of_features.pdf
Weakness of quantization-based approaches
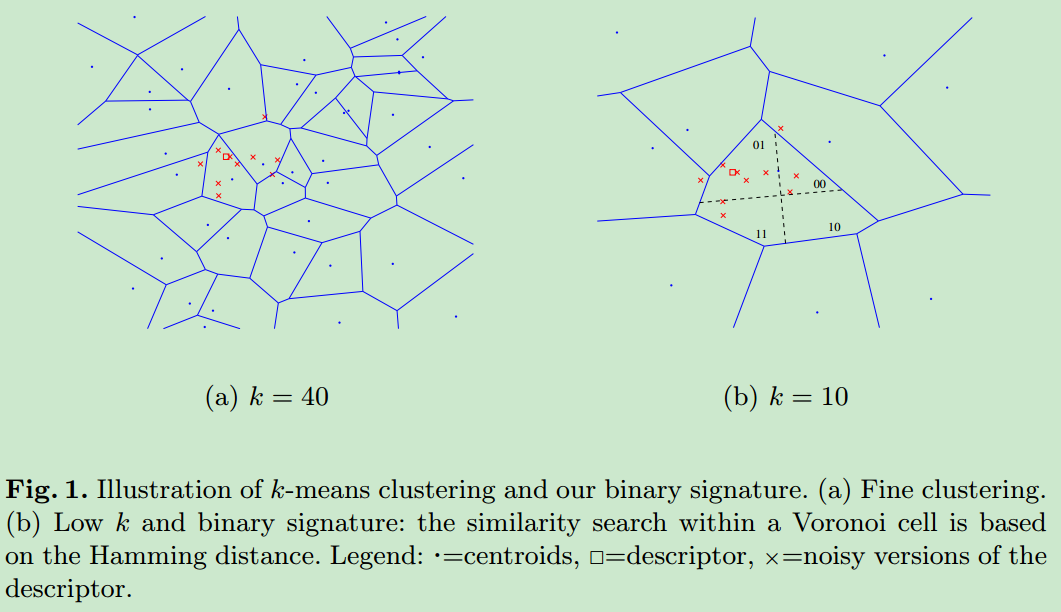
- 上述BoF model的方法对codebook size很敏感(就是那个聚类的簇数$K$)。如果$K$很小,则模型对噪声比较鲁棒,即即使数据有部分噪声,也会得到比较鲁棒的结果,但是可能导致模型对相似图像的区分能力不高(codebook表征图像的能力很差);但是如果$K$很大,则区分能力较大,但是可能会呆滞模型对噪声十分敏感。下图说明了这种情况。
Hamming embedding of local image descriptors
Hamming embedding是融合了$K$很小与$K$很大时模型的优势,使用$d_b$维的binary signature改善quantized index$q(x_i)$,得到$b(x_i) = (b_1(x_i), b_2(x_i), …, b_{d_b}(x_i))$。- 两个descriptor,$x$与$y$的hamming distance定义如下
$$h(b(x),b(y)) = \sum\limits_{i = 1}^{d_b} [1 - \delta _{b_i(x),b_i(y)}]$$
- 将descriptor从
Euclidean space映射到Hamming space,就称为Hamming Embedding,对于Euclidean space中最近邻的2个descriptor,也需要保证它们在Hamming space中的距离是很小的。 Hamming Embedding包含2个过程。- offline learning:在数据集上进行学习,得到一组固定的向量。
- online:计算
binary signature。
offline
生成$d_b \times d$的正交投影矩阵($d$是HE之前descriptor的维度,$d_b$是HE之后的维度)。首先生成一个符合高斯分布的$d\times d$的矩阵,对其进行QR分解,取矩阵Q的前$d_b$行,即得到我们需要的正交投影矩阵$P$。matlab实现方式如下
d = 64; db = 32; rnd_m = randn(d,db); [Q, ~] = qr( rnd_m ); P = Q(1:db,:);使用P将之前的descriptor $x_i$转化为$z_i$。$z_i$分配给最近的centroid $q(x_i)$,即之前聚类的结果(kmeans等)。
- 计算
projected descriptors的中值,作为HE的阈值:找到属于$q_l$的所有映射后descriptor,对于每个component $h(1 \le h \le d_b)$,计算其中值,得到$\tau _{h,l}$,矩阵$\tau$就是projected descriptors的中值矩阵。
online
- offline过程得到了$P(k \times d_b)$和$\tau (k \times d_b)$矩阵。对于给定的descriptor $x$,首先将其分配给最近的中心,假设为$q(x_i)$。
- 将$x$使用P矩阵进行映射,得到$z$,$z = Px$。$z$是$1 \times d_b$维的向量。
- 计算signature $b(x)$,计算方法如下:
$$b_i(x) = \begin{cases}
1,\;if\;{z_i} > \tau _{q(x),i}\\
0,\;otherwise
\end{cases} $$
- 由上面的步骤,一个descriptor就可以通过$q(x)$与$b(x)$同时进行表征,定义
HE matching function为
$${f_{HE}}(x,y) = \begin{cases}
tf - idf(q(x)),\;if\;q(x) = q(y)\;and\;h(b(x),b(y)) \le h_t\\
0,\;otherwise
\end{cases} $$
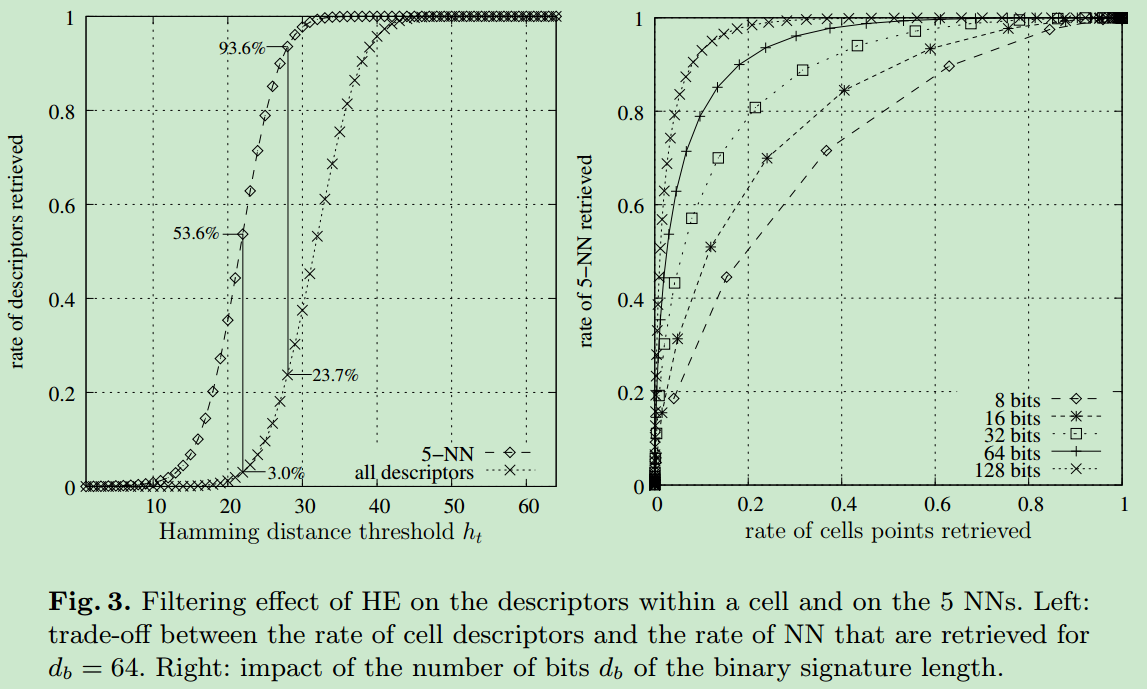
其中$h_t$是fixed Hamming threshold,满足$0 \le h_t \le d_b$。$h_t$需要足够大,保证x的Euclidean NNs都可以匹配上,同时又需要足够小,保证Voronoi cell中距离很远的点可以被过滤掉,下面的左图展示了$h_t$对检索率的影响,可以看出合适的$h_t$可以使得绝大部分的descriptor可以被过滤掉(HE方法可以过滤到绝大部分的descriptor,从而提升检索成功的概率)。右图显示了$d_b$对检索性能的影响,当然$d_b$越大,性能越好。